
対話型音声AI
デスクトップ対話 · 産業音声 · スマートホーム — エッジ多言語対話
エッジデバイスでの集音 + ローカルASR/TTS、エンドツーエンド0.3–0.5秒応答。シーン別にコンピュート性能を選び、距離別に集音方式を選択。クラウド不要で多言語対話と音声クローンを実現。
シナリオ概要
エッジデバイスでの集音、ローカルASR/TTS、多言語対話を組み合わせたターンキーソリューション。デスクトップ対話、産業用音声制御、スマートホームをカバー。既製モジュールで迅速に導入し、必要に応じてハードウェアカスタマイズで製品形態に適合。


エンドツーエンド低遅延
- エンドツーエンド0.3–0.5秒 — クラウド方式では実現困難
- ハードウェア一回の投資で、従量課金のAPI費用ゼロ
- 長時間安定稼働 — ネットワークに左右されない会話リズム

多言語すぐに使える
- 主要言語にゼロ設定で対応
- 音声品質を段階的に選択:マシン音 / シミュレート音 / リアル音
- 約10秒のサンプルで音声クローンが完了、専属の声を再現

ローカル処理の多面的メリット
- テキストのみ送信、クラウドの音声帯域とコストを節約
- 音声データは端末内に留保 — プライバシーとコンプライアンス要件に対応
- クラウド非依存 — 地域制限、レート制限、サービス終了のリスクなし
- オフライン・低帯域でも中核的な対話パイプラインは動作継続
応用シーン

多言語認識 · 同時通訳 · 自然音声合成
エッジでの多言語認識、リアルタイム翻訳、自然音声合成を実現。デスクトップ端末、会議端末、ガイドキオスクなどで双方向対話とクロス言語コミュニケーションを展開可能。
主なメリット
- 多言語認識:主要言語にすぐ対応
- 同時通訳:聞きながら翻訳、エンドツーエンド0.3–0.5秒
- 段階的音声品質:マシン音 / シミュレート音 / リアル音 — 予算に応じて選択

多言語認識
主要言語にゼロ設定で対応。中国語、英語、日本語、韓国語、スペイン語、フランス語、ドイツ語など主要輸出市場言語をカバー。

同時通訳
リアルタイムで聞きながら低遅延翻訳。越境会議、外国人接客、文化観光ガイドに最適。

音声ペルソナ
予算に応じて段階的に音声を選択。約10秒のサンプルでIP音声のクローンが即座に利用可能。

音声で機器制御と現場入力を完結 — 操作のハードルを低減
倉庫、工場、サーバールームなどの現場で、エッジ音声が複雑なUIやバーコードスキャナを代替。現場作業員は自然言語で入出庫登録、設備点検、巡回報告、危険通知を実施。ローカルASRが構造化テキストを出力し、WMS、MES、IoTプラットフォームに直接連携可能。
主なメリット
- 操作ハードルの低減:自然言語が複雑なUI、スキャナ、作業指示アプリを代替
- 弱いネットワークでも動作:ローカルASR、テキストのみ返送で現場帯域に依存しない
- 構造化出力:認識結果を直接WMS、MES、作業指示システムに投入

倉庫入出庫
SKU・数量の音声呼び出し確認 — 構造化テキストで直接WMSに書き込み。

設備点検
作業員が音声で機器状態を報告、AIが自動で点検フォームに記入し異常アラートを発報。

現場巡回報告
巡回フォームを音声入力;危険イベントをリアルタイムで指令センターに音声伝達。

即時ウェイク · ローカル制御 · 声紋パーソナライズ
XIAO ESP32S3を低消費電力ウェイクワードフロントエンドとして使用し、AIボックスのASR-TTSパイプラインを起動。声紋認識で家族メンバーを識別し個人設定を適用。Matter、HomeAssistant、Mi Home等のローカルプロトコルと連携。全コマンドをローカル処理 — オフラインでも日常使用に支障なし。
主なメリット
- ミリアンペア級ウェイクフロントエンド:ESP32S3 ESP-SR常駐、バッテリーで数ヶ月稼働
- 声紋パーソナライズ:家族メンバーを識別し個人設定を自動適用
- ローカル制御:Matter、HomeAssistant、Mi Home等のローカルプロトコルと連携済み

低消費電力ウェイク
ESP32S3がエッジでウェイクワードを検出してからメインシステムを起動、全体の省電力化を実現。

声紋メンバー認識
ローカル声紋データベースで家族メンバーを照合し、個人のシーン設定を自動読み込み。
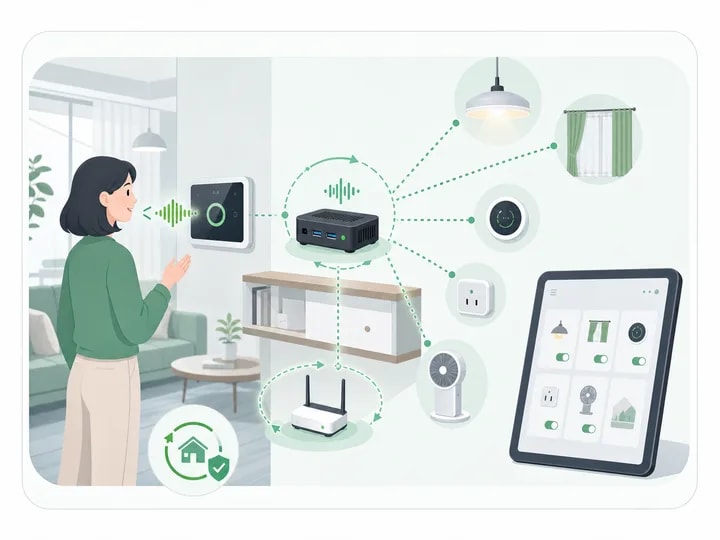
ローカルIoTオーケストレーション
Matter、HomeAssistant、Mi Homeと連携 — クラウドが切れてもスマートホーム制御は継続。
導入と選定
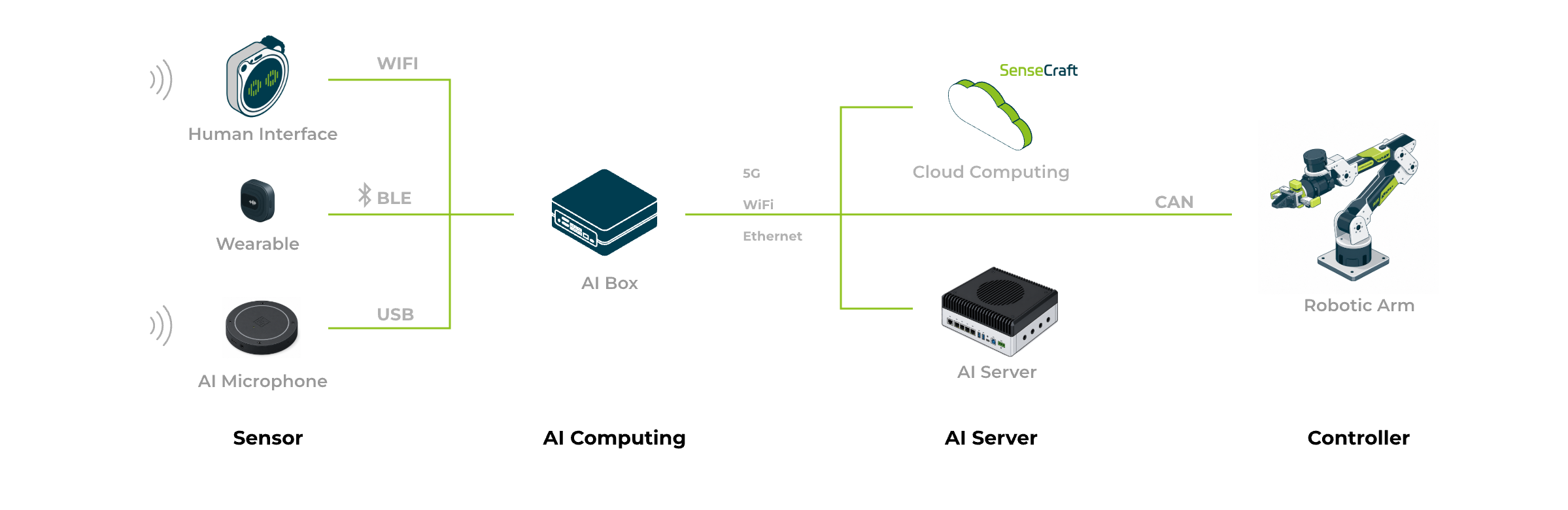
3つのアーキテクチャ形態:フロントエンド専用 / ハイブリッド / LLM一体型
音声処理の計算リソースをどこに置くかが、性能上限と単体BOMを決定します。一般的な3つの展開モデル:
主なメリット
- フロントエンド専用(ESP32S3):低消費電力で常駐、ウェイクワードと簡単なコマンドのみ対応。顧客独自のホストシステムまたはフロントエンド専用IoTデバイス向け。
- ハイブリッド(フロントエンド + 音声ボックス + リモートAI):エッジでウェイク・ASR・TTSを処理、複雑な意味理解とLLMはリモートで。コスパと拡張性が最良。
- LLM一体型(フロントエンド + 高性能AIボックス):1台のJetsonでASR + TTS + ローカルLLMの全パイプラインを実行。最も厳格なプライバシー、オフライン、コンプライアンス要件に対応。
| 製品 | グレード | 精度 | 音声機能 | 同時処理 | 試聴音色 | 参考価格 |
|---|---|---|---|---|---|---|
 XIAO ESP32-S3 Sense XIAO ESP32-S3 Sense | ウェイクフロントエンド(オンボードマイク) | — | ウェイクワード / コマンドワード | — | — | ~$10 |
 reRouter CM4 reRouter CM4 | エントリー級 | 基礎 | 単一言語ローカル文字起こし | — | マシン音 | $200–300 |
 reComputer AI R2130-12 reComputer AI R2130-12 | エントリー級 | 中程度 | 単一言語対話 | 単一 | シミュレート音 | ~$339 |
 reComputer RK3576 reComputer RK3576 | スタンドアロン版 | 良好 | 多言語対話 + ローカルLLM* | 単一 | シミュレート音 | ~$139 |
 reComputer RK3588 reComputer RK3588 | スタンドアロン版 | 良好 | 多言語対話 + ローカルLLM* | 単一 | シミュレート音 | ~$199 |
 reComputer J3011 reComputer J3011 | プロフェッショナル級 | 良好 | 多言語対話 | 2ch | シミュレート音 / リアル音 | ~$599 |
 reComputer J4012 reComputer J4012 | プロフェッショナル級 | 良好 | 多言語対話 + ローカルLLM | 2~3ch | シミュレート音 / リアル音 | $800–900 |
 reComputer J5012 reComputer J5012 | フラッグシップ級 | 優秀 | 多言語対話 + 高度なLLM | 高並列 | リアル音 | ~$2,000 |
シーン能力に応じてAIコンピュートボックスを選択
AIコンピュートボックスは対応音声能力によってランク分けされています。下表はランク、精度、対応能力、同時処理数、試聴音声品質、価格帯を記載(マイクとスピーカーの選定は次のタブを参照)。*RKシリーズのローカルLLMには1282 AIアクセラレーター拡張カード(アクセサリ)が必要です。
主なメリット
- ウェイク/コマンドワードのみ → ウェイクフロントエンド、約$10のオールインワン
- コスパ重視のスタンドアロン版 → RKシリーズ:多言語対話 + ローカルLLM、単一チャンネル、シミュレート音
- プロフェッショナル級リアル音声 → Jシリーズ:J3011はリアル音声と2chの同時処理に対応;J4012はローカルLLMと2~3chの同時処理に対応
- 高並列 + 高度なLLM → J5012フラッグシップ級、1台で全パイプラインを実行
| 製品 | タイプ | チップ | 集音 距離 | 収音 角度 | 内蔵 アンプ | コアアルゴリズム |
|---|---|---|---|---|---|---|
 reSpeaker Lite reSpeaker Lite | リニア 2マイク | XMOS XU316 | 3m | 180° | 5W | AEC · DoA |
 reSpeaker XVF3800 reSpeaker XVF3800 | 円形 4マイク | XMOS XVF3800 | 5m | 360° | 5W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Circular-4 reSpeaker Flex Circular-4 | 円形 4マイク | XMOS XVF3800 | 5m | 360° | 10W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Linear-4 reSpeaker Flex Linear-4 | リニア 4マイク | XMOS XVF3800 | 5m | 180° | 10W | AEC · DoA · Multi-beamforming |
reSpeakerシリーズの3つのコア優位性
主なメリット
- ① 優れたハードウェア集音能力 組み込みシナリオ専用設計のハードウェア構造が物理的にノイズ干渉を遮断。アレイ配置によるDOA音源定位と組み合わせることで、同種製品の中で明確な優位性を発揮します。
- ② オンボードAI音響アルゴリズム XMOSチップがAECエコーキャンセル・ノイズリダクション・ビームフォーミングをオンボードでリアルタイム処理。フロントエンドからクリーンな音声を出力し、バックエンドの認識誤差を低減します。
- ③ オープンエコシステム ファームウェアとSDKを開発者に公開。Seeedへの依存なしにSDKで自律的にパラメータ調整が可能。XIAO ESP32S3・Raspberry Pi・Jetsonおよびすべての USB / I²S 対応プラットフォームに対応し、既存ハードウェアへの柔軟な統合を実現します。
お問い合わせ
ハードウェアパートナーとしてうれしいです!